字符集编码发展
发展历程
ASCII
1963年 ANSI(美国国家标准学会)推出了ASCII(美国信息交换标准代码),作为计算机及其他设备的文本字符编码标准。
支持
- 0-9阿拉伯数字
- 大小写英文字母
- 常用英文符号
- 控制字符(负责换行、回车等特殊控制功能)
相关概念
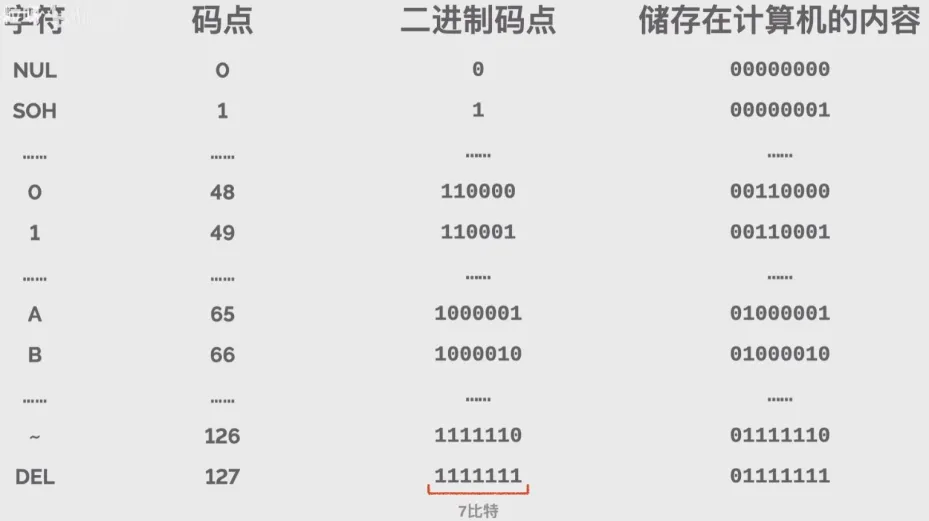
码点:每个字符的一个对应的数字(ASCII为0-127)。
字符集:标准所支持的所有字符及其对应码点的集合。
字符编码:从字符到计算机能够存储的内容之间的映射。
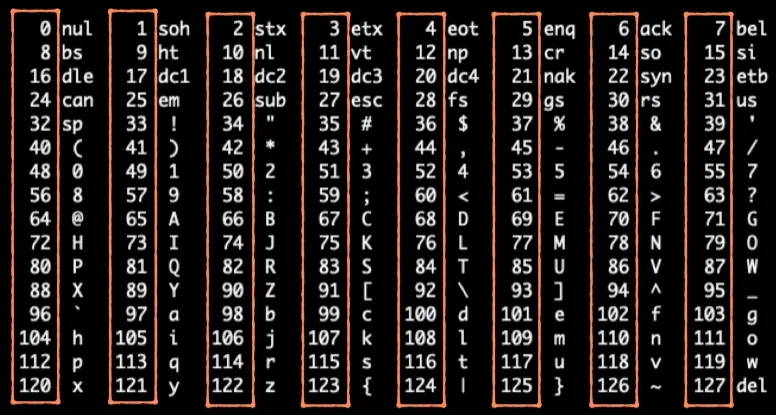
ASCII 字符集包含128个字符
其他编码标准
GB2312 编码标准:中国大陆国家标准总局制定,于1981年开始实施。
Big5 编码标准:港澳台地区1984年开始流行的大五码。
GBK 编码标准:GB2312 基础上进行扩展,收录了简繁汉字、日文、韩文等。
出现问题
计算机内同一个二进制数字,在不同的字符集中代表的可能是完全不同的字符。
需要更通用的字符编码,支持不同语言的文字。
Unicode
1991年 Unicode 字符集发布,囊括海量字符。
字符集只是字符及字符对应码点的集合,不代表字符一定会以对应码点被存储在计算机里。
字符编码才是真正从字符到计算机储存内容的映射
UTF-32 编码
所有字符都以 4 个字节(32bit)存储,位数不够则补0。
缺点:占用空间大
UTF-8 编码
1992 年诞生的可变长度编码,使用 1-6 个字节表示一个符号,字母使用 1 个字节,汉字使用 3 个字节(Unicode的改进方式,互联网使用最广)。
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为 0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。

1 | |
根据上面编码规则对照表,进行 UTF-8 编码和解码就简单多了。下面以汉字“汉”为例,具体说明如何进行 UTF-8 编码和解码。
“汉”的 Unicode 码点是 ``0x6c49(110 1100 0100 1001),通过上面的对照表可以发现,0x0000 6c49位于第三行的范围,那么得出其格式为1110xxxx 10xxxxxx 10xxxxxx。接着,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 用 0 补上。这样,就得到了“汉”的 UTF-8 编码为11100110 10110001 10001001,转换成十六进制就是0xE6 0xB7 0x89`。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位 1,那么连续有多少个 1,就表示该字符占用多少个字节。
优点:
- 兼容 ASCII,前128个字符与 ASCII 的一样,码点也一样,映射长度也一样;
- 节约空间,让码点小的字符也拥有更短的长度;
- 通过前缀信息,让计算机辨别各字符在内存中的总长度,解决分割不明问题。
彩蛋—“锟斤拷”形成原因
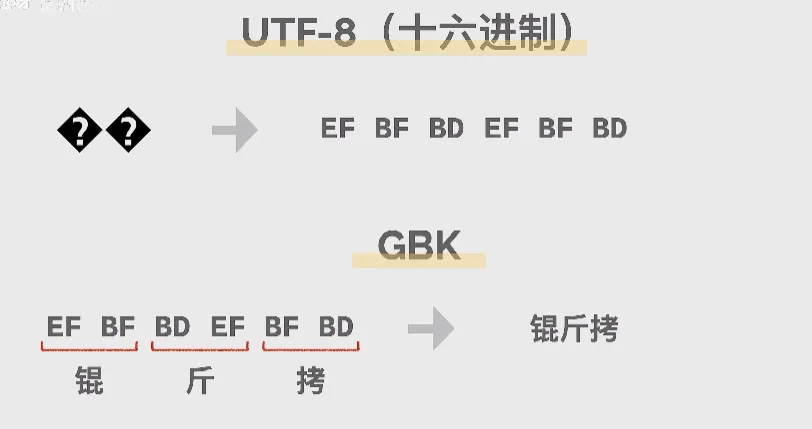
“锟斤拷”是著名的中文乱码,常见于 UTF-8 和中文编码(如:GBK)的转换过程中产生。
形成原因
- Unicode 字符集有一个特殊的替换符号”�”,专门用于表示无法识别或展示的字符。
- 有些编辑器在编码为 UTF-8 时,会把无法识别或展示的字符自动替换为这个符号,用于提示用户;
- � 的二进制表示为:
11101111 10111111 10111101; - � 的转换为十六进制表示为:
EF BF BD; - 如果两个替换符号连在一起”��”,内存里就出现:
EF BF BD EF BF BD; - GBK 编码中,每个汉字占用两个字节,
EF BF对应锟,BD EF对应斤,BF BD对应拷; - 如果文件使用 GBK 编码读取,就会把
EF BF BD EF BF BD转换为”锟斤拷“;
参考: