Java 数据类型
Java 基本数据类型
Java 中有 8 种基本数据类型,分别为:
6 种数字类型:
- 4 种整数型:
byte、short、int、long - 2 种浮点型:
float、double
- 4 种整数型:
1 种字符类型:
char1 种布尔型:
boolean
这 8 种基本数据类型的默认值以及所占空间的大小如下:
| 类型 | 占用存储空间 | 默认值 | 最小值 | 最大值 |
|---|---|---|---|---|
| byte | 1byte | 0 | -27-128 | 27 - 1127 |
| short | 2byte | 0 | -215-32768 | 215 - 132767 |
| int | 4byte | 0 | -231-2147483648 | 231 - 12147483647 |
| long | 8byte | 0L | -263…… | 263 - 1…… |
| float | 4byte | 0.0f | -1.4E-45 -3.403E38 | 3.4028235E38 |
| double | 8byte | 0.0d | -1.798E308 | 1.7976931348623157E308 |
| char | 2byte | ‘u0000’ | 0 \u0000 | 65535(216- 1)\uffff |
| boolean | 1bit | false | false | true |
像 byte、short、int、long能表示的最大正数都 -1 了。这是为什么呢?
这是因为在二进制补码表示法中,最高位是用来表示符号的(0 表示正数,1 表示负数),其余位表示数值部分。所以,如果我们要表示最大的正数,我们需要把除了最高位之外的所有位都设为 1。如果我们再加 1,就会导致溢出,变成一个负数。
另外,Java 的每种基本类型所占存储空间的大小不会像其他大多数语言那样随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是 Java 程序比用其他大多数语言编写的程序更具可移植性的原因之一(《Java 编程思想》2.2 节有提到)。
整型 - byte、short、int、long
byte:字节(1byte):8位、有符号的,以二进制补码表示的整数
short:短整型(2byte):16 位、有符号的,以二进制补码表示的整数
int:整型(4byte):32位、有符号的,以二进制补码表示的整数
long:长整型(8byte):64 位、有符号的,以二进制补码表示的整数
整型的使用细节
- Java 的整型常量默认为
int型,声明 long 型常量须在后加l或L; - Java 程序中变量声常明为
int型,除非不足以表示大数,才使用long; bit: 计算机中的最小存储单位。byte: 计算机中基本存储单元,1byte = 8bit。
浮点型 - float、double
float:4byte:单精度、32位、符合IEEE 754 标准的浮点数
double:8byte:双精度、64 位、符合 IEEE 754 标准的浮点数
浮点型使用细节
- 浮点数在机器中存放形式,浮点数 = 符号位 + 指数位 + 尾数位
- 尾数部分可能丢失,造成精度损失(小数都是近似值)
- 浮点数默认为
double类型,声明float型须在后面加上f或F。(数值加d表示double类型) - 浮点数有两种表示形式:
- 十进制数形式:如5.12 512.0f .512
- 科学计数法形式:如5.12e2(5.12*10^2)
- 科学记数法:结尾的”E+数字”表示E之前的数字要乘以10的多少次方。比如,3.14E-3就是3.14 x 10-3 =0.00314。
- 通常使用
double型,精度更高 - 比较浮点数的时候,不能使用“
==”操作符。(计算机 内存存储浮点数使用IEEE754标准,存在精度问题,在存储计算过程中容易引起较小的舍入误差)
- 使用Math.abs() 方法来计算两个浮点数之间差异的绝对值,如果这个差异在阈值范围之内,我们就认为两个浮点数是相等的。如:Math.abs(num1 - num2) < 0.0001
- 使用 BigDecimal 类的 compareTo() 方法对两个数进行比较,该方法将会忽略小数点后的位数。见示例1。(比如说 2.0 和 2.00 的位数不同,但它俩的值是相等的)
示例1
1 | |
字符型 - char
char:2byte:单一的 16 位 Unicode 字符
字符型使用细节
char用单引号' ',String字符串用双引号" "- 转义字符 ‘
\‘ ,将其后的字符转变为特殊字符型常量。如:char c = '\n' - Java 中,
char本质是一个整数,输出时是 unicode 编码对应的字符(因此可直接赋值char一个整数)
- Unicode与中文之间的相互转换工具:在线Unicode/中文转换工具 - 编码转换工具 - W3Cschool
- Unicode编码转换 - 站长工具
- 由3.可得,
char类型可进行运算。 - 字符型存储到计算机中,需要找到字符对应的码值(整数),比如
'a':
- 存储:
'a'–> 码值 97 –> 二进制 0110 0001 –> 存储
- 存储:
- 字符编码表:
- - ASCII 编码表 1 个字节表示,一个128个字符(实际上一个字节可以表示256个字符,只用了128个)
- Unicode 编码表 固定大小的编码,使用 2 个字节表示,字母和汉字统一占用 2 个字节(但这样浪费空间)。(Unicode兼容ASCII)
- utf-8 编码表:大小可变的编码,使用1-6个字节表示一个符号,字母使用 1 个字节,汉字使用 3 个字节(实际开发用得最多)(Unicode的改进方式,互联网使用最广)
- gbk 可以表示汉字,范围广,字母使用 1 个字节,汉字使用 2 个字节
- gb2312 可以表示汉字,gb2312 < gbk
- big5 码,繁体中文,tw hk
布尔型 - boolean
boolean:1bit: 1 位,作为一种标志来记录 true/false 情况
(准确讲是1byte,计算机处理数据的最小单位是 1 个字节)
事实上:boolean 占用多少字节取决于虚拟机本身的实现,《Java 虚拟机规范》提议:
- 如果 boolean 是 “单独使用”:boolean 被编译为 int 类型,占 4 个字节
- 如果 boolean 是以 “boolean 数组” 的形式使用:boolean 占 1 个字节
布尔型细节
- Java中不可以用 0 或者非 0 整数替代 false 和 true,这点和C、php等语言不同。
Java 类型转换
自动类型转换
自动类型转换:低精度数据类型 自动转换为 高精度数据类型:
- char –> int –> long –> float –> double
- byte –> short –> int –> long –> float –> double
示例2:
1 | |
自动类型转换细节
- 多种类型得数据混合运算时,系统自动将所有数据转换成精度(容量)最大的数据类型,然后再进行计算:
1 | |
- 当把精度(容量)大的数据类型赋值给精度(容量)小的数据类型时,就会报错。
- (
byte,short) 和char之间不会相互自动转换。 byte,short,char三者可以计算,在计算时首先转换为**int**类型。
1 | |
- boolean 不参与转换
- 自动提升原则:表达式结果的类型自动提升为操作数中最大的类型。
强制类型转换
自动类型转换的逆过程,将容量大的数据类型转换为容量小的数据类型。需要加上强制转换符(),但可能造成精度降低或溢出。
1 | |
基本数据类型和String类型的转换
- 基本类型转String类型
方法:直接拼接个双引号””
1 | |
- String类型转基本类型
方法:通过基本类型的包装类调用parseXX方法即可(每一个基本类型都对应一个包装类)
1 | |
String转换成char ==> 得到字符串的第一个字符 (利用charAt(n)方法,将字符串的第n个字符取出)
1 | |
- 注意
- 将
String类型转成基本数据类型时,要确保String类型能够转成有效的数据,比如可以把"123"转成一个整数,但是不能把"shit"转成一个整数。 - 如果格式不正确,就会抛出异常,程序终止。
包装类
- 在进行基本的数据计算时,开发者可以直接使用基本数据类型。
- 但是当需要和Java其他对象结合使用,如存入集合中,就需要将基础数据类型实例封装为Java对象,
- 为了面向对象的这一特性,基本数据类型中的每一个类型在
java.lang包中都有一个包装类,即将每个基本类型都包装成了一个类。八种基本类型对应包装类:Byte、Short、Integer、Long、Float、Double、Character、Boolean。
| 基本数据类型 | 包装类 | 接口 | 父类 | 接口 | 父类 |
| boolean | Boolean | Comparable | — | Serializable | Object |
| char | Character | ||||
| byte | Byte | Number | |||
| short | Short | ||||
| int | Integer | ||||
| long | Long | ||||
| float | Float | ||||
| double | Double |
基本类型和包装类型的区别
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中 [1]。 - 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是
null,而基本类型有默认值且不是null。 - 比较方式:对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
[1] 为什么说是几乎所有对象实例都存在于堆中呢?
这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
更多参考:JIT逃逸分析
⚠️ 注意:基本数据类型存放在栈中是一个常见的误区! 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆中。
1 | |
基本数据类型和包装类转换
- jdk5 前的手动装箱和拆箱方式。(装箱:基本类型 -> 包装类型;拆箱:包装类型 -> 基本类型)
- jdk5 及以后的自动装箱和拆箱方式。
- 自动装箱底层调用的是
valueOf方法,比如Integer.valueOf()。
1 | |
什么是自动拆装箱?
装箱:将基本类型用它们对应的引用类型包装起来
拆箱:将包装类型转换为基本数据类型
1 | |
注意:如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作。
浮点数运算的精度丢失风险
1 | |
原因:计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。
更多内容详见:浮点数
如何解决浮点数运算的精度丢失问题?
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到货币的场景)都是通过 BigDecimal 来做的。
1 | |
关于 BigDecimal 的详细介绍,参考:BigDecimal 详解。
超过 long 整型的数据应该如何表示?
基本数值类型都有一个表达范围,如果超过这个范围就会有数值溢出的风险。
在 Java 中,64 位 long 整型是最大的整数类型。
1 | |
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据。
相对于常规整数类型的运算来说,BigInteger 运算的效率会相对较低。
String类型和包装类转换
包装类(Integer 为例) -> String
1 | |
String -> 包装类(Integer)
1 | |
包装类缓存机制
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128, 127] 的相应类型的缓存数据,Character 创建了数值在 [0, 127] 范围的缓存数据,Boolean 直接返回 True or False。
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
所有整型包装类对象之间值的比较,全部使用 **equals** 方法比较。
经典案例
1 | |
valueOf()源码:
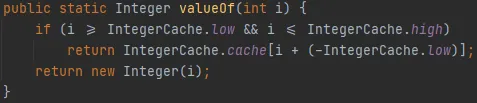
解读:
- 当传入的参数在 -128~127 范围时,不创建新对象直接返回cache数组对应的值。
- 当传入的参数不在 -128~127 范围时,直接创建新对象。
**IntegerCache.cache**数组(部分):
该数组由包装类Integer创建,大小为 256,存储了 -128~127
Character
1 | |
示例:判断字符串是否都为数字组成
1 | |