Numpy
1. Numpy 简介
NumPy 是一个由多维数组对象(ndarray)和处理这些数组的函数(function)集合组成的库。主要用来计算、处理一维或多维数组。
2. Numpy 安装
1 | |
在实际项目中, NumPy 通常与 SciPy 程序包一起使用,SciPy 可以看做对 NumPy 库的扩展,它在 NumPy 的基础上又增加了许多工程计算函数。因此将它们同时安装是一个不错的选择。
注意:在 Windows 下直接使用 pip 安装 SciPy 会发生报错,需要我们解决 SciPy 的依赖项问题,所以不推荐使用pip安装 SciPy 程序包。
首先我们要知道什么是 SciPy 栈?其实它是一个科学计算软件包的集成平台,这类平台囊括了常用的数值计算与机器学习库,比如 NumPy、Matplotlib、SciPy 库、IPython 等,并且它可以自动解决包之间的依赖问题。通过安装一个集成平台就可以实现上述所有软件包的安装。
常用的平台为 Anaconda(官网下载:https://www.anaconda.com/),是一个开源的 Python 发行版,它包含了 NumPy、SciPy 等180多个科学包及其依赖项。除了支持 Windows 外,也支持 Linux 和 Mac 系统。Anaconda 就目前应用较为广泛,因此建议安装。
Anaconda 的下载文件约 500 MB 左右,你可以选择安装 Miniconda,它是 Anaconda 的轻巧版,只需 40 余兆。
3. Numpy ndarray对象
NumPy 定义了一个 n 维数组对象,简称 ndarray 对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块,您可以使用索引或切片的方式获取数组中的每个元素。
ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列,常用的布局方式有两种,即按行或者按列。
3.1 创建ndarray对象
通过 NumPy 的内置函数 array() 可以创建 ndarray 对象,其语法格式如下:
1 | |
参数说明:
| 参数 | 描述说明 |
|---|---|
| object | 表示一个数组序列。 |
| dtype | 可选参数,通过它可以更改数组的数据类型。 |
| copy | 可选参数,表示数组能否被复制,默认是 True。 |
| order | 以哪种内存布局创建数组,有 3 个可选值,分别是 C(行序列)/F(列序列)/A(默认)。 |
| ndim | 用于指定数组的维度。 |
示例:
1 | |
3.2 ndim查看数组维数
1 | |
3.3 reshape数组变维
数组的形状指的是多维数组的行数和列数。reshape()函数可以改变多维数组行数和列数,从而达到数组变维的目的。
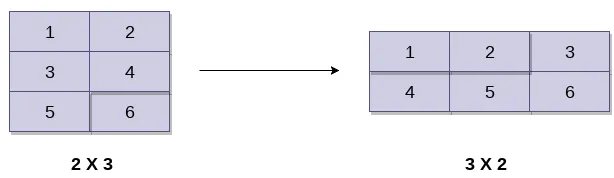
reshape()函数可以接受一个元组作为参数,用于指定了新数组的行数和列数:
1 | |
4. Numpy 数据类型
Numpy 作为 Python 的扩展包,它提供了比 Python 更加丰富的数据类型。
(略,http://c.biancheng.net/numpy/dtype.html)
4.1 数据类型(dtype)对象
数据类型对象(Data Type Object) 主要用来描述数组元素的数据类型、大小以及字节顺序。
1 | |
4.2 数据类型标识码
NumPy 中每种数据类型都有一个唯一标识的字符码:
| 字符 | 对应类型 |
|---|---|
| b | 代表布尔型 |
| i | 带符号整型 |
| u | 无符号整型 |
| f | 浮点型 |
| c | 复数浮点型 |
| m | 时间间隔(timedelta) |
| M | datatime(日期时间) |
| O | Python对象 |
| S,a | 字节串(S)与字符串(a) |
| U | Unicode |
| V | 原始数据(void) |
示例:使用数据类型标识码,创建一组结构化数据:
1 | |
4.3 定义结构化数据
通常情况下,结构化数据使用字段的形式来描述某个对象的特征。以下示例描述一位老师的姓名、年龄、工资的特征,该结构化数据其包含以下字段:
- str 字段:name
- int 字段:age
- float 字段:salary
1 | |
5. NumPy 数组属性
ndarray.shape
返回一个由数组维度构成的元组。如 2 行 3 列的二维数组可以表示为(2,3)。
示例,输出了数组的维度:
1 | |
通过 shape 属性修改数组的形状大小:
1 | |
ndarray.reshape()
NumPy 还提供了一个调整数组形状的 reshape() 函数。
1 | |
ndarray.ndim
返回数组的维数。
1 | |
ndarray.itemsize
返回数组中每个元素的大小(以字节为单位)。
1 | |
ndarray.flags
返回 ndarray 数组的内存信息,比如 ndarray 数组的存储方式,以及是否是其他数组的副本等。
1 | |
ndarray.dtype
ndarray.size
小结
1 | |
ndarray的转置
1 | |
- 在默认情况下,两者效果相同,但
transpose()可以指定交换的axis维度。 - 对于一维数组,两者均不改变,返回原数组。
- 对于二维数组,默认进行标准的转置操作。
- 对于多维数组
A,A.shape为(a,b,c,d,...,n),则转置后的shape为(n,...,d,c,b,a),即逆序。 - 对于
.transpose(),可以指定转置后的维度。语法:A.transpose((axisOrder1,...,axisOrderN)),其效果等同于np.transpose(A,(axisOrder1,...,axisOrderN)),(axisOrder)中是想要得到的索引下标顺序。效果详见例子。
示例,指定维度:
1 | |
a.transpose(1,2,0)与np.transpose(a, (1,2,0))效果相同。其shape在第一个维度即shape[0]上是原来的shape[1],第二维shape[1]是原来的shape[2],第三维shape[2]是原来的shape[0]。所以原shape为(3,2,4)。新的 shape为(2,4,3)。
参考: